















































Dateline Roorkee: A proposed sentiments analysis technique has achieved 92.83 percent accuracy for sentiment classification in Sanskrit text by the Indian Institute of Technology Roorkee (IIT Roorkee) researchers who have developed an efficient method for Sanskrit text sentiment analysis.
Sanskrit is one of the world’s most ancient languages; however, natural language processing tasks such as machine translation and sentiment analysis have not been explored. The proposed technique has achieved 87.50% accuracy for machine translation and 92.83% accuracy for sentiment classification.
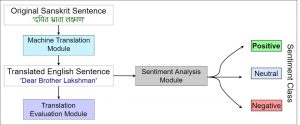
Sanskrit is one of the world’s most ancient languages; however, natural language processing tasks such as machine translation and sentiment analysis have not been explored for it to the full potential because of the unavailability of sufficient labeled data.
The research proposed a method that comprises models for machine translation, translation evaluation, and sentiment analysis. The team involved in this research are Prof. Balasubramanian Raman, Department of Computer Science and Engineering and his Ph.D. student Mr. Puneet Kumar, and M.Sc. student Mr. Kshitij Pathania, Department of Mathematics.
The machine translations have been used as cross-lingual mapping of the source and the target language. The obtained English translations are sufficiently mature and natural as the original English sentences. The model has been published as a Research Paper in a reputed peer-reviewed journal Applied Intelligence (DOI – https://doi.org/10.1007/s10489-022-04046-6)
Elaborating on the sentiment analysis model, Prof. Balasubramanian Raman, Department of Computer Science, IIT Roorkee, said, “We have trained our model to predict sentiment scores in the range of positive, neutral, or negative. And the model uses statistics, natural language processing, and machine learning to determine the sentiment with over 90% accuracy.”
The dataset to perform this research was taken from the Valmiki Ramayana website (https://www.valmiki.iitk.ac.in ) developed and maintained by the IIT Kanpur researchers. The future plans of the researchers are to exploit the morphological properties of Sanskrit for better classification using only root words with their respective suffixes and prefix. It is also planned to evaluate whether the morphological richness of Sanskrit is retained while translating to English. Moreover, the researchers also plan to obtain a model that discerns the context of words in multiple languages and provides word embeddings of lesser dimensions.








{kind=link}